ΓΈCEDEC 2016Γœ¥ιΩßΛρ±°ΛΛΓΛ ΖΑœΒΛΛρΤ…ΛύAIΓ÷≤ΕΛΈ≤«ΓΉΛœΛΛΛΪΛΥΛΖΛΤΚνΛιΛλΛΩΛΪ
 |
ΓΓΛΫΛσΛ NTTPCΞ≥ΞΏΞεΞΥΞ±ΓΦΞΖΞγΞσΞΚΛ§CEDEC 2016Λ«ΓΛΤ±Φ“ΛΈΞ·ΞιΞΠΞ…Λρ≥ηΆ―ΛΖΛΩΒΓ≥Θ≥ΊΫ§ΖΩAIΛΥ¥ΊΛΙΛκΞΜΞΟΞΖΞγΞσΓ÷ΓΊ≤ΕΛΈ≤«ΓΌΓΔΩΆΙ©ΧΒ«ΫΛδΛαΛκΛΟΛΤΛηΓΘΓΉΛρΦ¬ΜήΛΖΛΩΛΈΛ«ΓΛΚΘ≤σΛœΛΫΛΈΧœΆΆΛρΞλΞίΓΦΞ»ΛΖΛΩΛΛΓΘ≈–Ο≈ΛΖΛΩΛΈΛœΓΛNTTPCΞ≥ΞΏΞεΞΥΞ±ΓΦΞΖΞγΞσΞΚΛ«ΞΒΓΦΞ”ΞΙΞ·ΞξΞ®ΞΛΞΖΞγΞσΛρΟ¥≈ωΛΙΛκΙβΕΕΖ…Ά¥ΜαΛάΓΘ
 |
Γ÷ΩΆ¥÷ΛΈ…ΫΨπΛρΤ…ΛύAIΓΉΛρΧήΜΊΛΖΛΤ
 |
ΓΓΚρΚΘΛ«ΛœΓΛΓ÷Ξ«ΞΘΓΦΞΉΞιΓΦΞΥΞσΞΑΛΥΛηΛκAIΓΉΛρΜ»ΛΟΛΩΞ≠ΞψΞιΞ·ΞΩΓΦΛ»ΛΛΛΠΛΈΛβΛΛΛμΛΛΛμΫ–ΛΤΛ≠ΛΤΛΛΛκΓΘ
ΓΓΛ≥ΛΈΦξΛΈAIΛœΟ±ΑλΛΈΗΡά≠Λ«»Ω±ΰΛ§≤ηΑλ≈ΣΛάΛ»ΛΛΛΠΛΈΛ§Αλ»Χ≈ΣΛ …Ψ≤ΝΛ ΛΈΛάΛ§ΓΛΙβΕΕΜαΛιΛΈΞΝΓΦΞύΛœΛΫΛλΛάΛ»AIΛΈΗΡά≠Λ»ΛΖΛΤ Σ¬≠ΛξΛ ΛΛΛ»¥ΕΛΗΓΛΓ÷≤ΕάλΆ―ΓΉΛΈ»Ω±ΰΛρΦ®ΛΙAIΛρΧήΜΊΛΖΛΩΛΈΛάΛ»ΛΛΛΠΓΘΛόΛΩΓΛΗάΗλΛΥΆξΛκΛ≥Λ»Λ Λ·Γ÷¥ιΩßΛρ±°ΛΠΓΉΓ÷ ΖΑœΒΛΛρΜΓΛΙΛκΓΉΛηΛΠΛ ΛβΛΈΛρΚνΛμΛΠΛ»ΜνΛΏΛΤΛΛΛκΛΫΛΠΛ«ΛΔΛκΓΘ
 |
 |
 |
ΓΓΛΫΛΠΛΖΛΤΛ«Λ≠ΛΔΛ§ΛΟΛΩAIΛΥΞ≠ΞψΞιΞ·ΞΩΓΦΛρΓ»»οΛΜΓ…ΛλΛ–ΓΛΓ÷≤ΕΛΈ≤«ΓΉΛΈΛ«Λ≠ΛΔΛ§ΛξΛ»ΛΛΛΠΛοΛ±ΛάΓΘ
 |
 |
ΓΓΫ–≈ΗΛΈΤβΆΤΛ§Η«ΛόΛΟΛΩΛΈΛ§CEDEC 2016ΛΈ3ΫΒ¥÷ΝΑΛ»ΛΛΛΠΛ≥Λ»ΛβΛΔΛΟΛΤΓΛΞ«ΞβΛœΛΛΛμΛΛΛμΛ»ΤΆ¥”Ι©ΜωΛΥΛ ΛΟΛΤΛΣΛξΓΛΓ÷Ξ«ΓΦΞΩΛβΑλΫδΛΖΛΤΑλΡΧΛξΛΈΒΓ«ΫΛœΦ¬ΝθΛΖΛΩΛβΛΈΛΈΓΛΛόΛάΛόΛά≥ΊΫ§ΛœΫΫ §Λ«ΛœΛ ΛΛΓΉΛ»ΙβΕΕΜαΛœΫ“ΛΌΛΤΛΛΛΩΓΘ
ΓΓΚΘ≤σΛΈΞ÷ΓΦΞΙ≈ΗΦ®ΛœΓΛ≥ΊΫ§Ε·≤ΫΛρΖσΛΆΛΤΛΈΗχ≥ΪΛάΛΟΛΩΛ§ΓΛΚΘΗεΛœΛβΛΟΛ»άΚ≈ΌΛρΨεΛ≤ΛΤΛ·ΛκΛΈΛ«ΛΔΛμΛΠΓΘΞ≠ΞψΞιΞ·ΞΩΓΦΛœΓ÷ΟφΧνΞΖΞΙΞΩΓΦΞΚΛΈΜ–Υε2ΩΆ §ΛΈΞβΓΦΞΖΞγΞσΞ«ΓΦΞΩΛρΆ―Α’ΛΙΛκΛ≥Λ»Λ§Λ«Λ≠Λ ΛΪΛΟΛΩΛΈΛ«ΓΛΚΘ≤σΛœΥεΛΈΚμΒήΞΪΞΈΛΝΛψΛσΛάΛ±ΛΥΙ ΛΟΛΤΦ¬ΝθΛΖΛΩΓΉΛ»ΛΈΛ≥Λ»Λ«ΛΔΛκΓΘ
 |
ΓΓΛ…ΛΠΛ«ΛβΛΛΛΛΛ≥Λ»ΛάΛ§ΓΛΟφΧνΕηΧ±Λ»ΛΖΛΤΛœΓΛΓ÷ΟφΧνΕηΛΈΞ≠ΞψΞιΛ«…ΡΜζΛ§ΚμΒήΓΉΛ»ΛΛΛΠΛΈΛœΓΛ≈λΒΰ≈‘ΛΈΞ≠ΞψΞιΛ«…ΡΜζΛ§Ρ°≈ΡΛ»ΛΪΨ°≥όΗΕΛάΛ» ΙΛΪΛΒΛλΛΩΛ»Λ≠ΛΥΛβΜςΛΩΑψœ¬¥ΕΛ§Ψ·ΛΖΛΔΛκΓΘ
ΓΓΛΒΛΤΓΛΚΘ≤σΛΈΞ«ΞβΛΥΛΔΛΩΛΟΛΤΛœΓΛΞΑΞκΓΦΞΉ≤ώΦ“ΛΪΛιΝϊ≤ΜΛΥΕ·ΛΛΞόΞΛΞ·ΒΓΚύΛ Λ…ΛρΡ¥ΟΘΛΖΛΤΛœΛΛΛΩΛηΛΠΛάΛ§ΓΛ≤ώΨλΛ«ΛœΝϊ≤ΜΛ§ΖψΛΖΛΛΛ≥Λ»Λ§Ζϋ«ΑΛΒΛλΛΩΛΩΛαΓΛΞόΞΛΞ·ΛρΜ»ΛΟΛΩ≤ώœΟΛΥΛηΛκΞ≥ΞΏΞεΞΥΞ±ΓΦΞΖΞγΞσΛœΟφΜΏΛ»Λ ΛξΓΛΞ≠ΓΦΞήΓΦΞ…ΛΈΓΈY/NΓœΞ≠ΓΦΛΈΛΏΛ«ΛδΛξΦηΛξΛΙΛκΛ≥Λ»ΛΥΛ ΛΟΛΩΛ»ΛΛΛΠΓΘΛΩΛάΓΛΓ÷ΗάΗλΛΥΑΆ¬ΗΛΖΛ ΛΛΞ≥ΞΏΞεΞΥΞ±ΓΦΞΖΞγΞσΛρΩ ΛαΛκΛ»ΛΛΛΠΑ’ΧΘΛ«ΛœΛηΛΪΛΟΛΩΛΈΛ«ΛœΛ ΛΛΛΪΓΉΛ»ΙβΕΕΜαΛœΗλΛΟΛΤΛΛΛκΓΘ
ΓΓΚΘ≤σΓΛ≤ώœΟΛΜΛΚΛΥΛδΛξΦηΛξΛΙΛκΛΠΛ®Λ«Ϋ≈ΜκΛΒΛλΛΤΛΛΛκΛΈΛ§ΓΛΗάΗλΛΥΛηΛιΛ ΛΛΓΛΞΈΞσΞ–ΓΦΞ–ΞκΞ≥ΞΏΞεΞΥΞ±ΓΦΞΖΞγΞσΛάΓΘ
ΓΓΩΆ¥÷Τ±ΜΈΛΈΞ≥ΞΏΞεΞΥΞ±ΓΦΞΖΞγΞσΛ«ΛβΓΛ¬γ»ΨΛœΞΈΞσΞ–ΓΦΞ–ΞκΛ Μ≈ΝπΛδ ΖΑœΒΛΛ Λ…ΓΛΗάΗλΛΥΛηΛιΛ ΛΛ…τ §ΛρΜ»ΛΟΛΤΛΛΛκΛ»ΛΛΛΠΓΘΒΓ≥Θ≥ΊΫ§ΛρΜ»ΛΟΛΩΩΆΙ©ΟΈ«ΫΞ≠ΞψΞιΛΈ¬ΩΛ·Λ§ΗάΗλ≈ΣΛ ≤ώœΟΛρΦ¥ΛΥΛΖΛΤΛΛΛκΛΈΛΥ¬–ΛΖΓΛΛ≥ΛΠΛΛΛΟΛΩΞΈΞσΞ–ΓΦΞ–ΞκΛ Ξ≥ΞΏΞεΞΥΞ±ΓΦΞΖΞγΞσΛρΫ≈ΜκΛΖΛΩΛΈΛ§ΚΘ≤σΛΈΞΉΞμΞΗΞßΞ·Ξ»ΛΈΤΟΡßΛ»ΛβΛΛΛ®ΛκΛάΛμΛΠΓΘ
 |
ΓΓΕώ¬Έ≈ΣΛΥΛœΓΛΗΪΛΩΧήΛΪΛι¬ηΑλΑθΨίΛρΦηΤάΛΖΓΛ≤ώœΟΛΖΛ Λ§ΛιΛΫΛλΛρ δάΒΛΖΛΤΛΛΛ·Λ»ΛΛΛΟΛΩ¥ΕΛΗΛάΓΘ…ΫΨπΛΈ ―≤ΫΛ Λ…ΛρΤ…ΛΏΦηΛκΛ≥Λ»Λ«ΓΛΓ÷Εβ»±Λ«ΞΝΞψΞιΛΫΛΠΛάΛ»ΜΉΛΟΛΩΛ±Λ…ΓΛΦ¬ΛœΩΩΧΧΧήΛ ΩΆΛάΛΟΛΩΓΉΛ»ΛΛΛΟΛΩ¥ΕΛΗΛΥΓΛΑθΨίΛΈ ―≤ΫΛρ¥ΕΛΗΦηΛλΛκΛηΛΠΛ AIΛΈΦ¬ΝθΛρΧήΜΊΛΖΛΤΛΛΛκΛ»ΓΛΙβΕΕΜαΛœΗλΛΟΛΤΛΛΛΩΓΘ
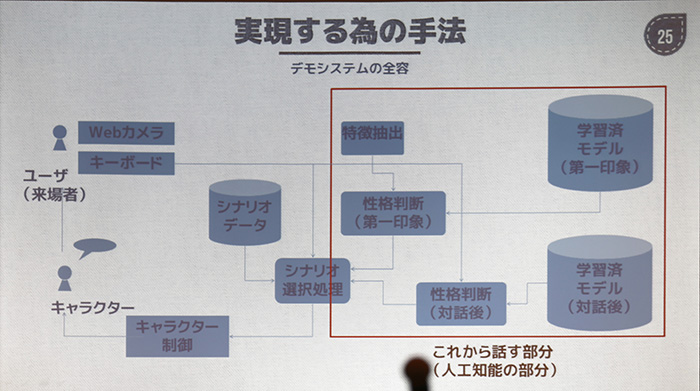 |
ΓΓ≤ηΝϋΛΪΛι≤ΩΛΪΛρ»ΫΟ«ΛΙΛκΨλΙγΛΈΒΓ≥Θ≥ΊΫ§Λ»ΛΛΛΠΛΈΛœΓΛΛΩΛ»Λ®Λ–¬γΈΧΛΈ≤Χ ΣΛΈ≤ηΝϋΛρΆ―Α’ΛΖΓΛ≤ηΝϋΛ»Γ÷Λ≥ΛλΛœΞξΞσΥù˻ΛΛΛΟΛΩΨπ σΛρΞΎΞΔΛΥΛΖΛΤ¬γΈΧΛΥΈ°ΛΖΙΰΛύΛ≥Λ»ΛΥΛηΛξΓΛΛ…ΛΠΛΛΛΟΛΩΤΟΡßΛρΜΐΛΟΛΩ≤ηΝϋΛ§ΞξΞσΞ¥Λ«ΛΔΛκΛΪΛ»ΛΛΛΠΛ≥Λ»ΛρAIΛ§ΦΪ §Λ«»ΫΟ«Λ«Λ≠ΛκΛηΛΠΛΥΛΖΛΤΛΛΛ·ΞΛΞαΓΦΞΗΛάΓΘΤΟΡßΛρΦΪΤΑΟξΫ–ΛΙΛκΛΥΛœΛΛΛ·ΛΡΛΪΛΈ ΐΥΓΛ§ΛΔΛκΛ§ΓΛΚΘ≤σΛΈΞΉΞμΞΗΞßΞ·Ξ»Λ«ΛœΩßΛΈΗϊ«έΞ«ΓΦΞΩΛρΆ―ΛΛΛΤΛΛΛκΛ»ΛΈΛ≥Λ»ΓΘΛΒΛΙΛ§ΛΥάΗΞ«ΓΦΞΩΛΈΛόΛόΛ«ΛœΫηΆΐΛ«Λ≠Λ ΛΛΛΈΛ«ΓΛΛΔΛιΛΪΛΗΛα≈§άΎΛΥΞ«ΓΦΞΩΛράΑΆΐΛΖΛΤΆΩΛ®ΛΆΛ–Λ ΛιΛ ΛΛΓΘ
ΓΓΛΩΛάΛΫΛΠΛΙΛκΛ≥Λ»Λ«ΓΛΩΆ¥÷Λ§Γ÷Λ…Λ≥ΛΈΩßΛ§ΓΉΛ»ΛΪΓ÷Λ…ΛΠΛΛΛΠΖΝΛάΛΟΛΩΛιΓΉΛ»ΛΛΛΟΛΩΜΊΡξΛρΡΨάήΆΩΛ®ΛΚΛ»ΛβΓΛ¬ΩΛ·ΛΈΞ«ΓΦΞΩΛΪΛιΜΊΡξΛΒΛλΛΩ ΐΥΓΛ«ΦΪΤΑ≈ΣΛΥΤΟΡßΛρΟξΫ–ΛΖΛΤ»ΫΟ«ΛΖΛΤΛ·ΛλΛκΛηΛΠΛΥΛ ΛκΓΘ
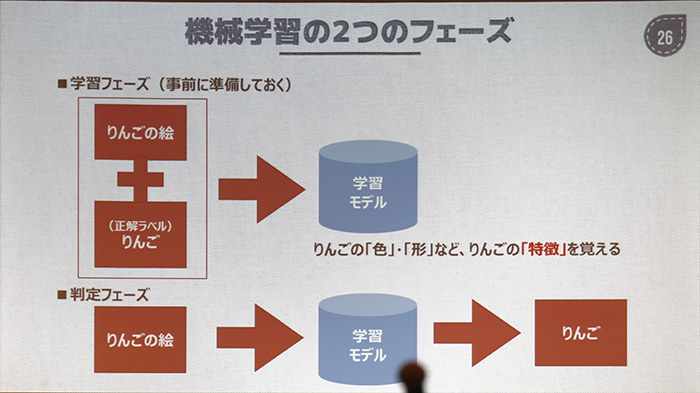 |
ΓΓΚΘ≤σΛΈAIΛœ¥ιΓ ΛΈ≤ηΝϋΓΥΛΪΛιά≠≥ Λρ≥δΛξΫ–ΛΙΛοΛ±ΛάΛ§ΓΛΛόΛΚΓΛ¬ηΑλΑθΨίΛρΤάΛκ…τ §ΛœΓΛΞΪΞαΞιΛΪΛιΦηΛξΙΰΛσΛά¥ιΞ«ΓΦΞΩΛρ128ΓΏ128Ξ…ΞΟΞ»≤ρΝϋ≈ΌΛ«Ά―Α’ΛΖΓΛΛΫΛλΛ» Χ≈”Ι‘ΛΟΛΩά≠≥ Ω«Ο«Ζκ≤ΧΛ»ΛρΝ»ΛΏΙγΛοΛΜΛΤΒΓ≥Θ≥ΊΫ§ΛΒΛΜΛκΛ≥Λ»Λ«ΓΛ¥ιΛΈΤΟΡßΛΪΛιά≠≥ ΛρΩδΡξΛΙΛκΛ»ΛΛΛΠ ΐΥΓΛρΚΈΆ―ΛΖΛΤΛΛΛκΓΘ
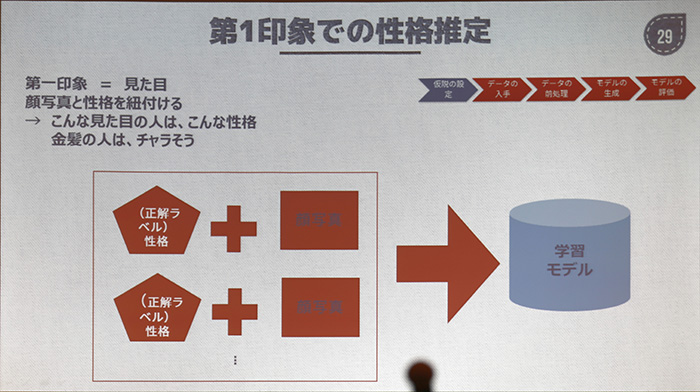 |
ΓΓΛΝΛ ΛΏΛΥΓΛά≠≥ »ΫΡξΛΥΛœ5ΑχΜ“ΞβΞ«ΞκΛ§ΚΈΆ―ΛΒΛλΛΤΛΣΛξΓΛ
- ΨπΤΑά≠
- ≥ΑΗΰά≠
- ≥Ϊ ϋά≠
- Ρ¥œ¬ά≠
- Ε– Όά≠
Λ»ΛΛΛΟΛΩΆΉΝ«ΛΈ≥δΙγΛ«ά≠≥ Λρ»ΫΡξΛΙΛκΓΘΚΘ≤σΛΈΦ¬ΝθΛ«ΛœΓΛ5ΆΉΝ«ΛΈΩτΟΆΟφΓΛ≈–œΩΛΒΛλΛΤΛΛΛκ≥ΤΆΉΝ«ΛΈ ΩΕ―ΩτΟΆΛΪΛιΚ«Λβ¬γΛ≠Λ·–ΣΈΞΛΖΛΤΛΛΛκΛβΛΈΛρΓΛΓ÷ΤΟΡß≈ΣΛ ά≠≥ ΆΉΝ«ΓΉΛ»ΛΖΛΤΞ‘ΞΟΞ·ΞΔΞΟΞΉΛΙΛκΦξΥΓΛρΆ―ΛΛΛΤΛΛΛκΛΫΛΠΛάΓΘ
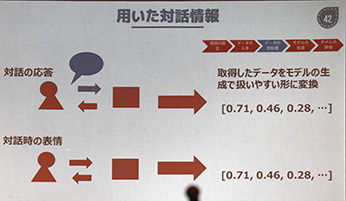
ΓΓΛ ΛΣΓΛ¥ιΨπ σΛœ3ΥϋΦΓΗΒΛβΛΈΞ«ΓΦΞΩΛ»Λ ΛξΓΛΓ÷ExcelΓΉΛ«”»Λ®ΛκΛ Λι3ΥϋΞΪΞιΞύΛΈΞ«ΓΦΞΩΛΥΝξ≈ωΛΙΛκΛΩΛαΓΛΞ«ΓΦΞΩΛρΗΚΛιΛΙ…§ΆΉΛ§ΛΔΛκΓΘ
ΓΓΛΫΛ≥Λ«ΚΈΆ―ΛΖΛΤΛΛΛκΛΈΛœΓΛΕ»≥ΠΛ«ΛβΛηΛ·Μ»ΛοΛλΛκΞΔΞκΞ¥ΞξΞΚΞύΛ«ΓΛΦγΆΉΛ ΆΉΝ«ΛάΛ±Λρ»¥Λ≠Ϋ–ΛΙΦγά° §≤ράœΓ PCFΓΥΛΥΛηΛΟΛΤΝξ¥ΊΛΈ«ωΛΛΆΉΝ«ΛρΛΫΛ°ΆνΛ»ΛΖΛΩΖκ≤ΧΓΛΞ«ΓΦΞΩΈΧΛρ0.1ΓσΛΥΑΒΫΧΛΖΛΩΜΰ≈άΛ«ΗΒΞ«ΓΦΞΩΛΥ¬–ΛΖΛΤ70ΓσΛΈάΚ≈ΌΛρ ίΜΐΛ«Λ≠ΛΤΛΛΛκΛ»ΛΛΛΠΓΘ
 |
 |
 |
 |
 |
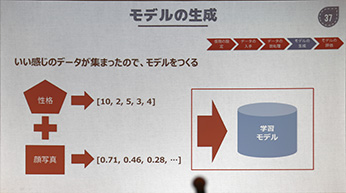
ΓΓΛΫΛβΛΫΛβ¥ιΛ»ά≠≥ Λ«Νξ¥Ί¥ΊΖΗΛ§ΛΔΛκΛΈΛΪΛ»ΛΛΛΟΛΩΛ»Λ≥ΛμΛΪΛιΛΝΛγΛΟΛ»ΒΩΧδΛœΛΔΛΟΛΩΛΈΛάΛ§ΓΛΛ«Λ≠ΛΔΛ§ΛΟΛΩΞβΞ«ΞκΛΪΛιΆΫ¬§ΛΒΛλΛΩΟΆΛ»Φ¬ΚίΛΈΟΆΛ»ΛΈ ΩΕ―ΗμΚΙΛœ7ΓΝ16ΓσΡχ≈ΌΛ»ΛΈΛ≥Λ»Λ«ΓΛΛύΛΖΛμΛΪΛ ΛξΙβΛΛΝξ¥Ί¥ΊΖΗΛ§ΤάΛιΛλΛΤΛΛΛκΛ≥Λ»Λ§ §ΛΪΛκΓΘΓ÷¬ηΑλΑθΨίΓΉΛ»ΛΛΛΟΛΩΛβΛΈΛœ¥ιΛΈ¬ΛΚνΦΪ¬ΈΛηΛξΛβ≤ώœΟΛδΜ≈ΝπΛ Λ…ΛΈ ΖΑœΒΛΛ§άξΛαΛκ…τ §Λ§¬γΛ≠ΛΛΛ»ΜΉΛΟΛΤΛΛΛΩΛΈΛάΛ§ΓΛΤΟΡß≈άΟξΫ–Λ«Λ≥ΛλΛάΛ±Ά≠Α’ΛΥΟξΫ–Λ«Λ≠ΛκΛ»ΛΛΛΠΛ≥Λ»ΛΥΛœΕΟΛ≠ΛάΓΘ
 |
 |
ΓΓΦ¬ΚίΛΈΞ«ΞβΛΈΆΆΜ“ΛœΓΛΑ ≤ΦΛΈΛηΛΠΛ ΛβΛΈΛΥΛ ΛΟΛΤΛΛΛκΓΘ
ΓΓΞ«ΞβΛΈΆΆΜ“ΛρΗΪΛΤΛΛΛκΛ»ΓΛΩΆΛΥΛηΛΟΛΤ¬ηΑλΑθΨίΛœΛΒΛόΛΕΛόΛ ΛΈΛάΛ§ΓΛ≤ώœΟΗεΛΈΖκ≤ΧΛ«ΛœΛ…ΛΠΛβΓ÷Εα¥σΛξΛ§ΛΩΛΛΓΉΓ÷ΩΩΧΧΧήΓΉΓ÷Ξ≥ΞσΞΒΞ–ΓΉΛ Λ…ΛΈΖχΛαΛ …Ψ≤ΝΛ§¬ΩΛ·Λ ΛΟΛΤΛΛΛΩΓΘΛ≥ΛλΛœΓΛΜωΝΑΛΈ≥ΊΫ§ΚύΈΝΛ»ΛΖΛΤΞΒΞσΞΉΞκΛ«Μ»Ά―ΛΖΛΩΦ“ΑςΛΥ30¬ε40¬εΛ§¬ΩΛΪΛΟΛΩΛ≥Λ»ΛδΓΛ≤ΜάΦΤΰΈœΛρΛδΛαΛΤΓΛΞ≠ΓΦΞήΓΦΞ…ΛΈΓΈY/NΓœΞ≠ΓΦΛάΛ±ΛρΜ»ΛΠΛηΛΠΛΥΛΖΛΩΛ≥Λ»ΛΈ±ΤΕΝΛ«ΛœΛ ΛΛΛΪΛ»ΛΈΛ≥Λ»ΛάΛΟΛΩΓΘ
ΓΓΛΩΛάΓΛ ΙΛΛΛΩ»œΑœΛ«ΛœΓΛ ΩΕ―ΛΪΛιΛΈΑψΛΛΛρΛβΛΟΛΤά≠≥ Λρ≥δΛξΫ–ΛΖΛΤΛΛΛκΛ»ΛΈΛ≥Λ»Λ ΛΈΛ«ΓΛΛΏΛσΛ ΩΩΧΧΧήΛ»»ΫΡξΛΒΛλΛΤΛΖΛόΛΠΛ»ΛΛΛΠΛ≥Λ»ΛœΓΛ λΫΗΟΡΛΈΞ«ΓΦΞΩΛ§ΛηΛέΛ…ΛœΛΟΛΝΛψΛ±ΛΤΛΛΛ ΛΛΛ»ΛΣΛΪΛΖΛ·Λ ΛΟΛΤΛΖΛόΛΠΓΘΛ…ΛΝΛιΛΪΛ»ΛΛΛ®Λ–ΓΛ≤ΜάΦΤΰΈœΛ§Λ Λ·Λ ΛΟΛΩΛΈΛ«ΓΛ…ΫΨπΛΈΤΰΈœΛ§…‘ΫΫ §ΛΥΛ ΛΟΛΩΛ»ΛΛΛΠΛ≥Λ»Λ ΛΈΛάΛμΛΠΓΘ
ΓΓΛ ΛΣΚΘ≤σΛΈΞ«ΞβΛœΓΛ¬ηΑλΑθΨίΛ«ΛΈ¥ι≤ηΝϋΛΪΛιΛΈά≠≥ »ΫΡξΛ»ΓΛ≤ώœΟΛρΙ‘ΛΟΛΤΛΪΛιΛΈ δάΒΛ§Ι‘ΛοΛλΛΩ»ΫΡξΛΈ2ΛΡΛ§ΤάΛιΛλΛκΛβΛΈΛ»Λ ΛΟΛΤΛΣΛξΓΛΕώ¬Έ≈ΣΛΥΝξΦξΛΥΙγΛοΛΜΛΤ≤ώœΟΛΙΛκΛηΛΠΛ Λ≥Λ»ΛœΛόΛάΦ¬ΝθΛΒΛλΛΤΛΛΛ ΛΛΓΘΨ≠Άη≈ΣΛΥΛœ»ΫΡξΖκ≤ΧΛΈΆ≠ΗζΆχΆ―ΛΥΛηΛΟΛΤΓΛ»σΗάΗλΨπ σΛΪΛι¬ΩΛ·ΛΈΛ≥Λ»Λρ»ΫΟ«Λ«Λ≠ΛκAIΛΥά°ΡΙΛΖΛΤΛΛΛ·ΛΈΛάΛμΛΠΓΘ
 |
ΓΓΞ≠ΞψΞιΞ·ΞΩΓΦΛœΓΛNTTΞΑΞκΓΦΞΉΛΈ≤ΜάΦ«ßΦ±ΓΠΙγά°ΞΫΞ’Ξ»ΞΠΞßΞΔΛρΆχΆ―ΛΖΛΤ≤ΜάΦΛρΫ–ΛΖΛΤΛΛΛκΓΘ≥ΈΛΪΓΛNTTΖœΛΈ≤ΜάΦΙγά°ΒΜΫ―ΛœΞ―ΞιΞαΓΦΞΩΛ»ΛΖΛΤ¥ΕΨπΛ Λ…ΛρΆΩΛ®ΛκΛ≥Λ»ΛβΛ«Λ≠ΛΩΛœΛΚΛ ΛΈΛ«ΓΛΛΫΛΈΛΠΛΝΛβΛΟΛ»Ξ®ΞβΓΦΞΖΞγΞ ΞκΛ ≤ώœΟΛ§ΖΪΛξΙ≠Λ≤ΛιΛλΛκΛηΛΠΛΥΛ Λκ≤Ρ«Ϋά≠ΛβΛΔΛξΛΫΛΠΛάΓΘ
ΓΓΤ±Φ“Λ«ΛœΓΛΛ≥ΛΈΛηΛΠΛ ΒΜΫ―ΛΈ±ΰΆ―ΛΥΚίΛΖΛΤΞ―ΓΦλΠΓΦΛρ γΫΗΛΖΛΤΛΛΛκΛΈΛ«ΓΛΞ≠ΞψΞιΞ·ΞΩΓΦΞ”ΞΗΞΆΞΙΛΥΩΖ≈Η≥ΪΛ§ΛβΛΩΛιΛΒΛλΛκΛΈΛβ±σΛΛΛ≥Λ»Λ«ΛœΛ ΛΛΛΈΛΪΛβΛΖΛλΛ ΛΛΓΘ
